pacman::p_load(sf, terra, gstat, automap,
tmap, viridis, tidyverse)In-class Exercise 7
Overview
isohyet map is a surface map of the same precipitation: rain, snow, and others. Figure below is an isohyet map showing to spatial distribution of total monthly rainfall of Singapore in February 2024.
.png)
In order to prepare an isohyet map, spatial interpolation will be used. Spatial interpolation is the process of using points with known values to estimate values at other unknown points. For example, to make a rainfall above, we will not find enough evenly spread weather stations to cover the entire region. Spatial interpolation can estimate the rainfall at locations without recorded data by using known rainfall readings at nearby weather stations (see figure_temperature_map). This type of interpolated surface is often called a geostatistical surface. Elevation data, temperature, property prices, air quality index and population density are other types of data that can be computed using interpolation.
.png)
There are many interpolation methods. In this hands-on exercise, two widely used spatial interpolation methods called Inverse Distance Weighting (IDW) and kriging will be introduce. If you are looking for additional interpolation methods, please refer to the ‘Further Reading’ section at the end of this topic.
Getting Started
In this in-class exercise, beside tidyverse, viridis, sf and tmap libaries, two new R packages will be used, they are:
terra is a replacement of the raster package. It has a very similar, but simpler, interface, and it is faster than raster. In this hands-on exercise, it will be used to create grid (also known as raster) objects as the input and output of spatial interpolation.
gstat, an r packages for spatial and spatio-temporal geostatistical modelling, prediction and simulation. In this in-class exercise, it will be used to perform spatial interpolation.
automap, an r package for performing automatic variogram modelling and kriging interpolation.
The Data
Three data sets will be used in this exercise, they are:
- RainfallStation.csv provides location information of existing rainfall stations in Singapore. The data is downloaded from Meteological Service Singapore.
- DAILYDATA_202402.csv provides weather data are rainfall stations for the month February, 2024. The data is also downloaded from Meteological Service Singapore.
- MPSZ-2019 contains planning subzone boundary of URA Master Plan 2019. It is downloaded from data.gov.sg. The original data is in kml format.
Importing rainfall station data
In the code chunk below, read_csv() of readr package is used to import RainfallStation.csv. rfstations, the output object is in tibble data.frame format.
rfstations <- read_csv("data/aspatial/RainfallStation.csv")Importing rainfall record data
In the code chunk below, read_csv() of readr package is used to import DAILYDATA_202402.csv. rfdata, the output object is in tibble data.frame format.
rfdata <- read_csv("data/aspatial/DAILYDATA_202402.csv") %>%
select(c(1, 5)) %>%
group_by(Station) %>%
summarise(MONTHSUM = sum(`Daily Rainfall Total (mm)`)) %>%
ungroup()
Note
- select() of dplyr package is used to retain column 1 and 5 of the input data.
- group_by() and summarise() of dplyr package are used to compute the total monthly rainfall from Daily Rainfall Total (mm) field. The output is stored in a new field called MONTHSUM.
Converting aspatial data into geospatial data
Next, left_join() of dplyr is used to join rfstations to rfdata by using the code chunk below.
rfdata <- rfdata %>%
left_join(rfstations)
Note
Because Station field is available in both rfstations and rfdata, by() argument of left_join() is not needed.
In the code chunk below, st_as_sf() of sf package is used to convert rfdata into a simple feature data.frame object called rfdata_sf.
rfdata_sf <- st_as_sf(rfdata,
coords = c("Longitude",
"Latitude"),
crs= 4326) %>%
st_transform(crs = 3414)
Note
- For
coordsargument, it is important to map the X (i.e. Longitude) first, then follow by the Y (i.e. Latitude). crs = 4326indicates that the source data is in wgs84 coordinates system.st_transform()of sf package is then used to transform the source data from wgs84 to svy21 projected coordinates system.- svy21 is the official projected coordinates of Singapore. 3414 is the EPSG code of svy21.
Importing planning subzone boundary data
In the code chunk below, st_read() of sf package is used to import MPSZ-2019 shapefile into R. The output is called mpsz2019. It is in polygon feature tibble data.frame format.
mpsz2019 <- st_read(dsn = "data/geospatial",
layer = "MPSZ-2019") %>%
st_transform(crs = 3414)Reading layer `MPSZ-2019' from data source
`C:\AlexeiJason\ISSS608-VAA\In-class_Ex\In-class_Ex07\data\geospatial'
using driver `ESRI Shapefile'
Simple feature collection with 332 features and 6 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 103.6057 ymin: 1.158699 xmax: 104.0885 ymax: 1.470775
Geodetic CRS: WGS 84
Note
- The source data is in wgs84 coordinates system, hence
st_tranform()of sf package is used to theo output sf data.frame into svy21 project coordinates system.
Visualising the data prepared
It is always a good practice to visualise the data prepared. In the code chunk below, tmap functions are used to create a dot map showing locations of rainfall station in Singapore.
tmap_options(check.and.fix = TRUE)
tmap_mode("view")
tm_shape(rfdata_sf) +
tm_dots(col = "red")tmap_mode("plot")In the code chunk below, tmap functions are used to create a quantitative dot map of rainfall distribution by rainfall station in Singaspore.
tmap_options(check.and.fix = TRUE)
tmap_mode("view")
tm_shape(mpsz2019) +
tm_borders() +
tm_shape(rfdata_sf) +
tm_dots(col = 'MONTHSUM')tmap_mode("plot")Spatial Interpolation: gstat method
In this section, you will gain hands-on experience on performing spatial interpolation by using gstat package. In order to perform spatial interpolation by using gstat, we first need to create an object of class called gstat, using a function of the same name: gstat. A gstat object contains all necessary information to conduct spatial interpolation, namely:
- The model definition
- The calibration data
Based on its arguments, the gstat function “understands” what type of interpolation model we want to use:
- No variogram model → IDW
- Variogram model, no covariates → Ordinary Kriging
- Variogram model, with covariates → Universal Kriging
The complete decision tree of gstat, including several additional methods which we are not going to use, is shown in the figure below.
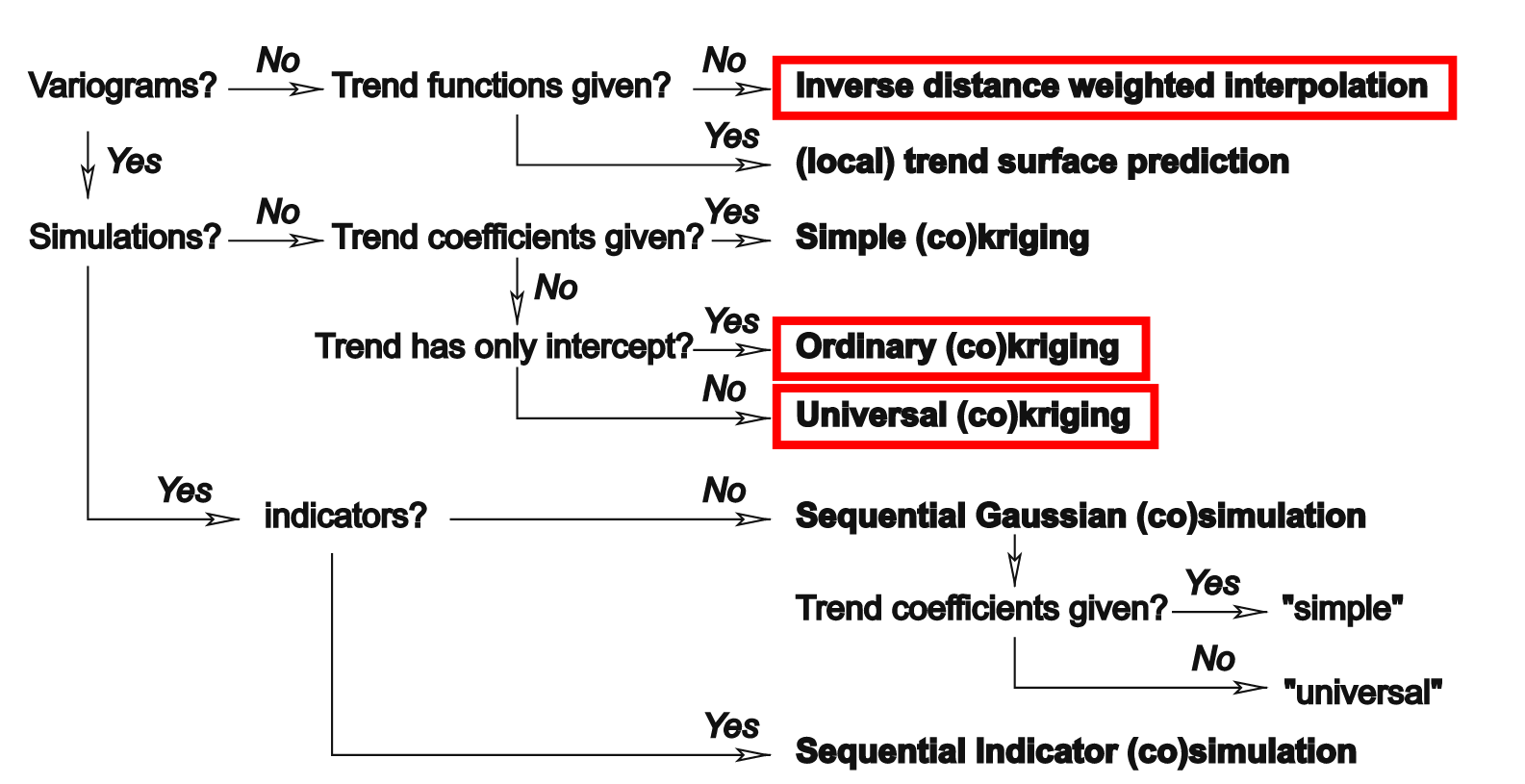
Data preparation
To getting start, we need create a grid data object by using rast() of terra package as shown in the cod chunk below.
grid <- terra::rast(mpsz2019,
nrows = 690,
ncols = 1075)
gridclass : SpatRaster
dimensions : 690, 1075, 1 (nrow, ncol, nlyr)
resolution : 49.98037, 50.01103 (x, y)
extent : 2667.538, 56396.44, 15748.72, 50256.33 (xmin, xmax, ymin, ymax)
coord. ref. : SVY21 / Singapore TM (EPSG:3414) Next, a list called xy will be created by using xyFromCell() of terra package.
xy <- terra::xyFromCell(grid,
1:ncell(grid))
head(xy) x y
[1,] 2692.528 50231.33
[2,] 2742.509 50231.33
[3,] 2792.489 50231.33
[4,] 2842.469 50231.33
[5,] 2892.450 50231.33
[6,] 2942.430 50231.33
Note
xyFromCell() gets coordinates of the center of raster cells for a row, column, or cell number of a SpatRaster. Or get row, column, or cell numbers from coordinates or from each other.
Lastly, we will create a data frame called coop with prediction/simulation locations by using the code chunk below.
coop <- st_as_sf(as.data.frame(xy),
coords = c("x", "y"),
crs = st_crs(mpsz2019))
coop <- st_filter(coop, mpsz2019)
head(coop)Simple feature collection with 6 features and 0 fields
Geometry type: POINT
Dimension: XY
Bounding box: xmin: 25883.42 ymin: 50231.33 xmax: 26133.32 ymax: 50231.33
Projected CRS: SVY21 / Singapore TM
geometry
1 POINT (25883.42 50231.33)
2 POINT (25933.4 50231.33)
3 POINT (25983.38 50231.33)
4 POINT (26033.36 50231.33)
5 POINT (26083.34 50231.33)
6 POINT (26133.32 50231.33)Inverse Distance Weighted (IDW)
The method
In the IDW interpolation method, the sample points are weighted during interpolation such that the influence of one point relative to another declines with distance from the unknown point you want to create.
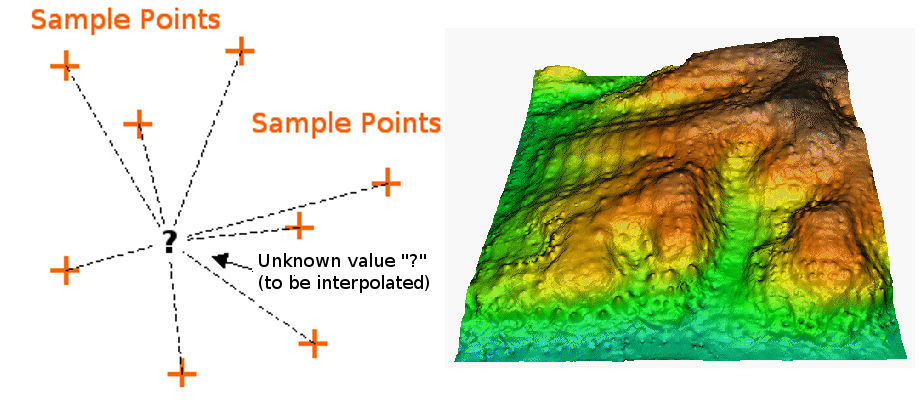
Weighting is assigned to sample points through the use of a weighting coefficient that controls how the weighting influence will drop off as the distance from new point increases. The greater the weighting coefficient, the less the effect points will have if they are far from the unknown point during the interpolation process. As the coefficient increases, the value of the unknown point approaches the value of the nearest observational point.
It is important to notice that the IDW interpolation method also has some disadvantages: the quality of the interpolation result can decrease, if the distribution of sample data points is uneven. Furthermore, maximum and minimum values in the interpolated surface can only occur at sample data points. This often results in small peaks and pits around the sample data points.
Working with gstat
We are going to use three parameters of the gstat function:
- formula: The prediction “formula” specifying the dependent and the independent variables (covariates)
- data: The calibration data
- model: The variogram model
Keep in mind that we need to specify parameter names, because these three parameters are not the first three in the gstat function definition.
For example, to interpolate using the IDW method we create the following gstat object, specifying just the formula and data:
g = gstat(formula = annual ~ 1, data = rainfall)
Tip
In R, formula objects are used to specify relation between objects, in particular—the role of different data columns in statistical models. A formula object is created using the ~ operator, which separates names of dependent variables (to the left of the ~ symbol) and independent variables (to the right of the ~ symbol). Writing 1 to the right of the ~ symbol, as in ~ 1, means that there are no independent variables38.
In the code chunk below,
res <- gstat(formula = MONTHSUM ~ 1,
locations = rfdata_sf,
nmax = 5,
set = list(idp = 0))
Important
Spatial interpolation is not a rocket science, students should try to explore the method by changing nmax argument in order to understand how the final surface map will be affected by different nmax values.
Now that our model is defined, we can use predict() to actually interpolate, i.e., to calculate predicted values. The predict function accepts:
- A raster—stars object, such as dem
- A model—gstat object, such as g
The raster serves for two purposes:
- Specifying the locations where we want to make predictions (in all methods), and
- Specifying covariate values (in Universal Kriging only).
resp <- predict(res, coop)[inverse distance weighted interpolation]resp$x <- st_coordinates(resp)[,1]
resp$y <- st_coordinates(resp)[,2]
resp$pred <- resp$var1.pred
pred <- terra::rasterize(resp, grid,
field = "pred",
fun = "mean")Now, we will map the interpolated surface by using tmap functions as shown in the code chunk below.
tmap_options(check.and.fix = TRUE)
tmap_mode("plot")
tm_shape(pred) +
tm_raster(alpha = 0.6,
palette = "viridis")
Kriging
The method
Kriging is one of several methods that use a limited set of sampled data points to estimate the value of a variable over a continuous spatial field. An example of a value that varies across a random spatial field might be total monthly rainfall over Singapore. It differs from Inverse Distance Weighted Interpolation discussed earlier in that it uses the spatial correlation between sampled points to interpolate the values in the spatial field: the interpolation is based on the spatial arrangement of the empirical observations, rather than on a presumed model of spatial distribution. Kriging also generates estimates of the uncertainty surrounding each interpolated value.
In a general sense, the kriging weights are calculated such that points nearby to the location of interest are given more weight than those farther away. Clustering of points is also taken into account, so that clusters of points are weighted less heavily (in effect, they contain less information than single points). This helps to reduce bias in the predictions.
The kriging predictor is an “optimal linear predictor” and an exact interpolator, meaning that each interpolated value is calculated to minimize the prediction error for that point. The value that is generated from the kriging process for any actually sampled location will be equal to the observed value at this point, and all the interpolated values will be the Best Linear Unbiased Predictors (BLUPs).
Kriging will in general not be more effective than simpler methods of interpolation if there is little spatial autocorrelation among the sampled data points (that is, if the values do not co-vary in space). If there is at least moderate spatial autocorrelation, however, kriging can be a helpful method to preserve spatial variability that would be lost using a simpler method (for an example, see Auchincloss 2007, below).
Kriging can be understood as a two-step process:
- first, the spatial covariance structure of the sampled points is determined by fitting a variogram; and
- second, weights derived from this covariance structure are used to interpolate values for unsampled points or blocks across the spatial field.
Kriging methods require a variogram model. A variogram (sometimes called a “semivariogram”) is a visual depiction of the covariance exhibited between each pair of points in the sampled data. For each pair of points in the sampled data, the gamma-value or “semi-variance” (a measure of the half mean-squared difference between their values) is plotted against the distance, or “lag”, between them. The “experimental” variogram is the plot of observed values, while the “theoretical” or “model” variogram is the distributional model that best fits the data.
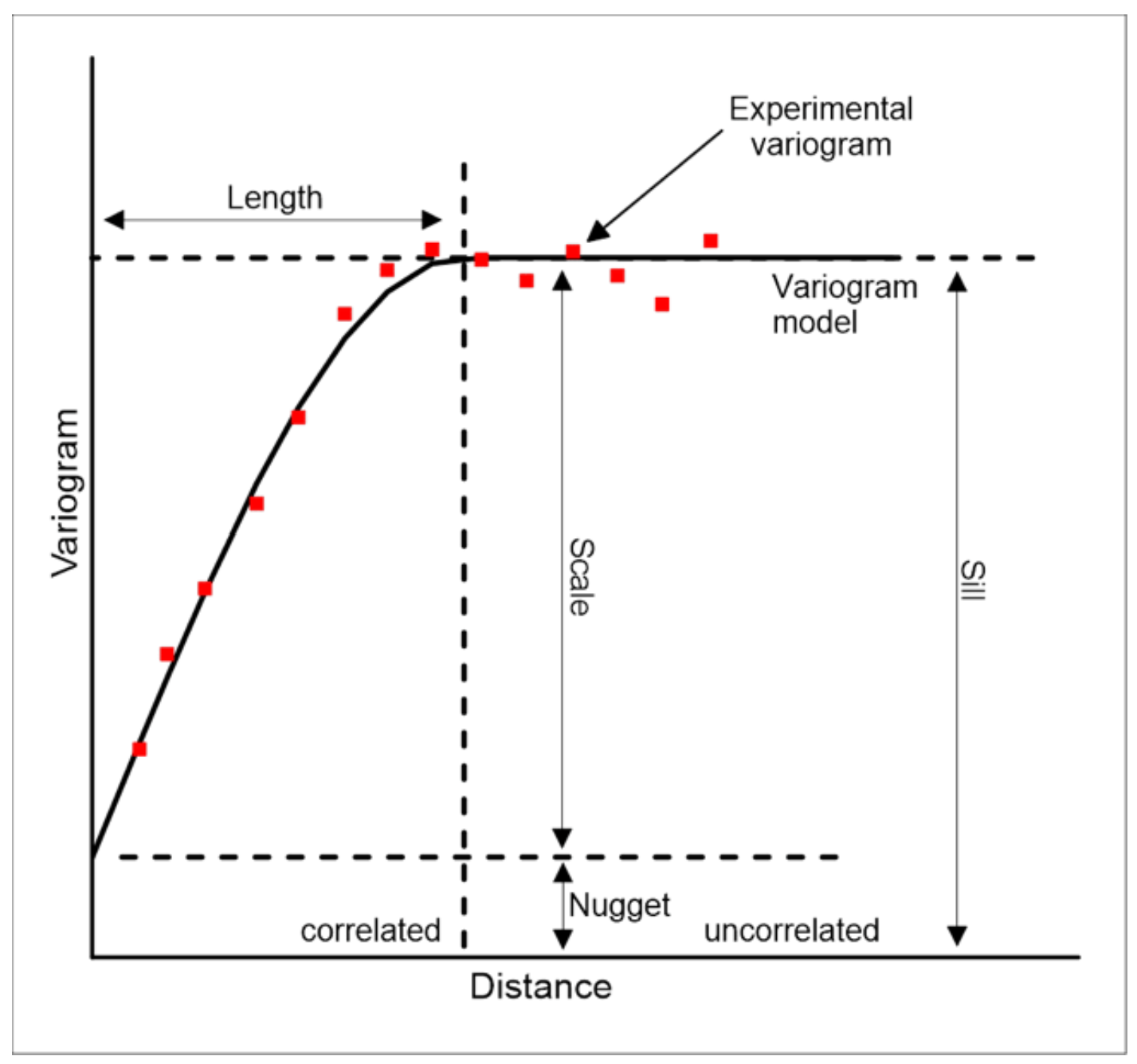
Working with gstat
Firstly, we will calculate and examine the empirical variogram by using variogram() of gstat package. The function requires two arguments:
- formula, the dependent variable and the covariates (same as in gstat, see Section 12.2.1)
- data, a point layer with the dependent variable and covariates as attributes
as shown in the code chunk below.
v <- variogram(MONTHSUM ~ 1,
data = rfdata_sf)
plot(v)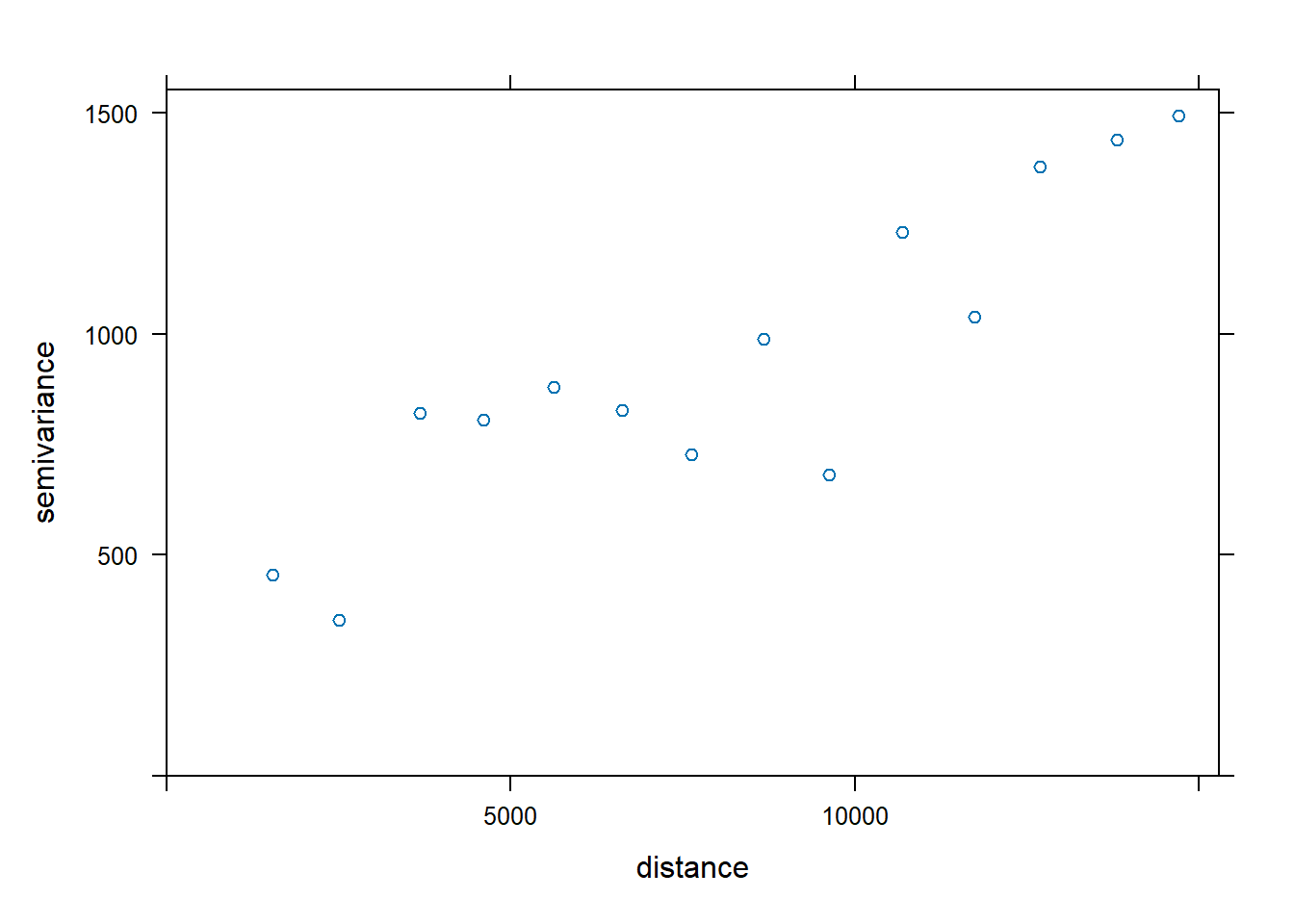
We can then compare the plot with the theoretical models below.
With reference to the comparison above, am empirical variogram model will be fitted by using fit.variogram() of gstat package as shown in the code chunk below.
fv <- fit.variogram(object = v,
model = vgm(
psill = 0.5,
model = "Sph",
range = 5000,
nugget = 0.1))
fv model psill range
1 Nug 0.1129190 0.000
2 Sph 0.5292397 5213.396
Important
Spatial interpolation is not a rocket science, students should try to explore the method by changing psill, model, range, nugget arguments in order to understand how the final surface map will be affected by different options used.
We can visualise how well the observed data fit the model by plotting fv using the code chunk below.
plot(v, fv)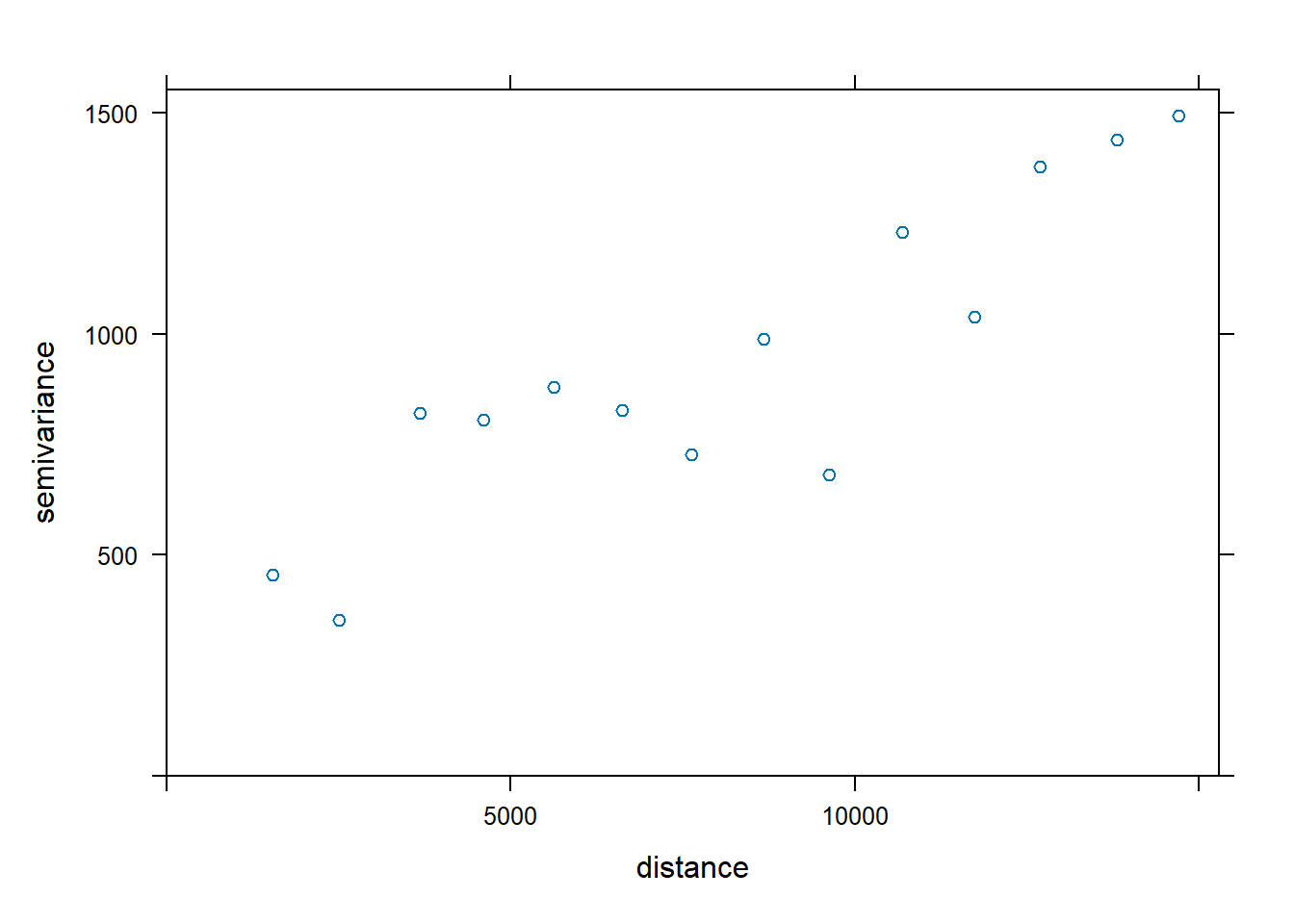
The plot above reveals that the empirical model fits rather well. In view of this, we will go ahead to perform spatial interpolation by using the newly derived model as shown in the code chunk below.
k <- gstat(formula = MONTHSUM ~ 1,
data = rfdata_sf,
model = fv)
kdata:
var1 : formula = MONTHSUM`~`1 ; data dim = 43 x 2
variograms:
model psill range
var1[1] Nug 0.1129190 0.000
var1[2] Sph 0.5292397 5213.396Once we are happy with the results, predict() of gstat package will be used to estimate the unknown grids by using the code chunk below.
resp <- predict(k, coop)[using ordinary kriging]resp$x <- st_coordinates(resp)[,1]
resp$y <- st_coordinates(resp)[,2]
resp$pred <- resp$var1.pred
resp$pred <- resp$pred
respSimple feature collection with 314019 features and 5 fields
Geometry type: POINT
Dimension: XY
Bounding box: xmin: 2692.528 ymin: 15773.73 xmax: 56371.45 ymax: 50231.33
Projected CRS: SVY21 / Singapore TM
First 10 features:
var1.pred var1.var geometry x y pred
1 131.0667 0.6608399 POINT (25883.42 50231.33) 25883.42 50231.33 131.0667
2 130.9986 0.6610337 POINT (25933.4 50231.33) 25933.40 50231.33 130.9986
3 130.9330 0.6612129 POINT (25983.38 50231.33) 25983.38 50231.33 130.9330
4 130.8698 0.6613782 POINT (26033.36 50231.33) 26033.36 50231.33 130.8698
5 130.8092 0.6615303 POINT (26083.34 50231.33) 26083.34 50231.33 130.8092
6 130.7514 0.6616697 POINT (26133.32 50231.33) 26133.32 50231.33 130.7514
7 130.6965 0.6617971 POINT (26183.3 50231.33) 26183.30 50231.33 130.6965
8 130.6446 0.6619131 POINT (26233.28 50231.33) 26233.28 50231.33 130.6446
9 130.5958 0.6620184 POINT (26283.26 50231.33) 26283.26 50231.33 130.5958
10 132.5484 0.6542154 POINT (25033.76 50181.32) 25033.76 50181.32 132.5484
Note
resp is a sf tibble data.frame with point features.
In order to create a raster surface data object, rasterize() of terra is used as shown in the code chunk below.
kpred <- terra::rasterize(resp, grid,
field = "pred")
kpredclass : SpatRaster
dimensions : 690, 1075, 1 (nrow, ncol, nlyr)
resolution : 49.98037, 50.01103 (x, y)
extent : 2667.538, 56396.44, 15748.72, 50256.33 (xmin, xmax, ymin, ymax)
coord. ref. : SVY21 / Singapore TM (EPSG:3414)
source(s) : memory
name : last
min value : 72.77826
max value : 195.53284
Note
The output object kpred is in SpatRaster object class with a spatial resolution of 50m x 50m. It consists of 1075 columns and 690 rows and in SVY21 projected coordinates system.
Mapping the interpolated rainfall raster
Finally, tmap functions are used to map the interpolated rainfall raster (i.e. kpred) by using the code chunk below.
tmap_options(check.and.fix = TRUE)
tmap_mode("plot")
tm_shape(kpred) +
tm_raster(alpha = 0.6,
palette = "viridis",
title = "Total monthly rainfall (mm)") +
tm_layout(main.title = "Distribution of monthly rainfall, Feb 2024",
main.title.position = "center",
main.title.size = 1.2,
legend.height = 0.45,
legend.width = 0.35,
frame = TRUE) +
tm_compass(type="8star", size = 2) +
tm_scale_bar() +
tm_grid(alpha =0.2)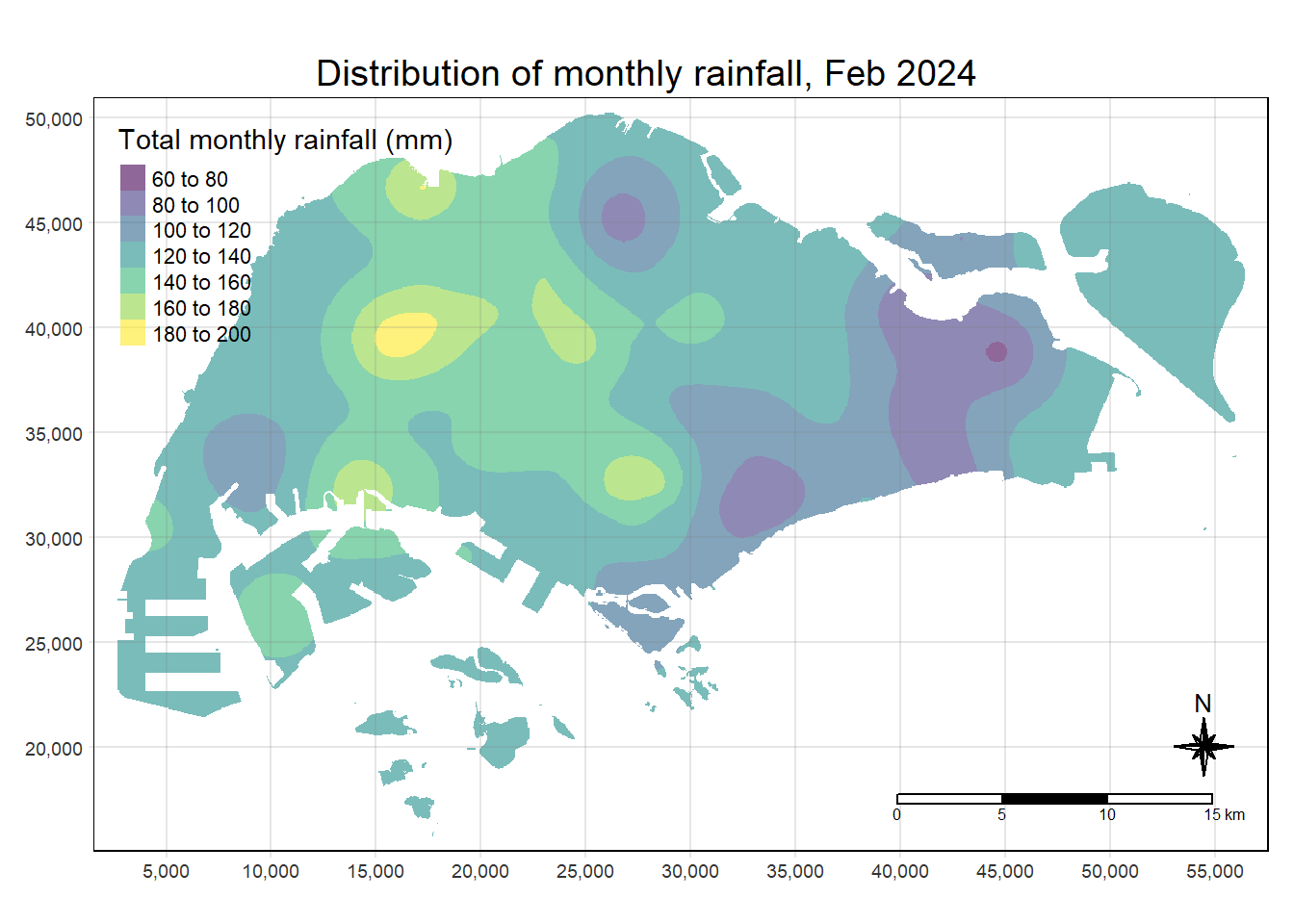
Automatic variogram modelling
Beside using gstat to perform variogram modelling manually, autofirVariogram() of automap package can be used to perform varigram modelling as shown in the code chunk below.
v_auto <- autofitVariogram(MONTHSUM ~ 1,
rfdata_sf)
plot(v_auto)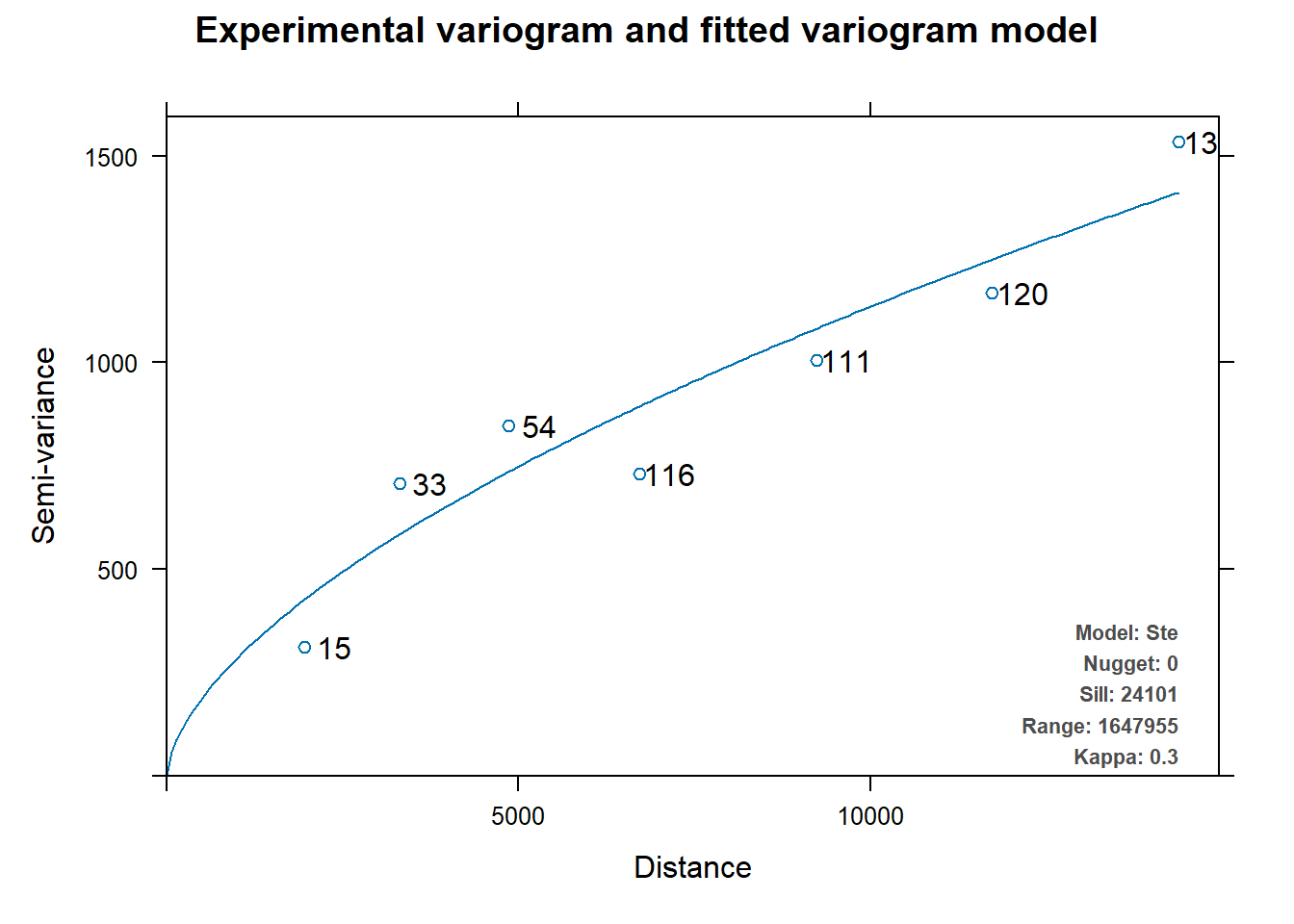
v_auto$exp_var
np dist gamma dir.hor dir.ver id
1 15 1957.436 311.9613 0 0 var1
2 33 3307.349 707.7685 0 0 var1
3 54 4861.368 848.1314 0 0 var1
4 116 6716.531 730.3969 0 0 var1
5 111 9235.708 1006.5381 0 0 var1
6 120 11730.199 1167.5988 0 0 var1
7 135 14384.636 1533.5903 0 0 var1
$var_model
model psill range kappa
1 Nug 0.00 0 0.0
2 Ste 24100.71 1647955 0.3
$sserr
[1] 0.2178294
attr(,"class")
[1] "autofitVariogram" "list" k <- gstat(formula = MONTHSUM ~ 1,
model = v_auto$var_model,
data = rfdata_sf)
kdata:
var1 : formula = MONTHSUM`~`1 ; data dim = 43 x 2
variograms:
model psill range kappa
var1[1] Nug 0.00 0 0.0
var1[2] Ste 24100.71 1647955 0.3resp <- predict(k, coop)[using ordinary kriging]resp$x <- st_coordinates(resp)[,1]
resp$y <- st_coordinates(resp)[,2]
resp$pred <- resp$var1.pred
resp$pred <- resp$pred
kpred <- terra::rasterize(resp, grid,
field = "pred")tmap_options(check.and.fix = TRUE)
tmap_mode("plot")
tm_shape(kpred) +
tm_raster(alpha = 0.6,
palette = "viridis",
title = "Total monthly rainfall (mm)") +
tm_layout(main.title = "Distribution of monthly rainfall, Feb 2024",
main.title.position = "center",
main.title.size = 1.2,
legend.height = 0.45,
legend.width = 0.35,
frame = TRUE) +
tm_compass(type="8star", size = 2) +
tm_scale_bar() +
tm_grid(alpha =0.2)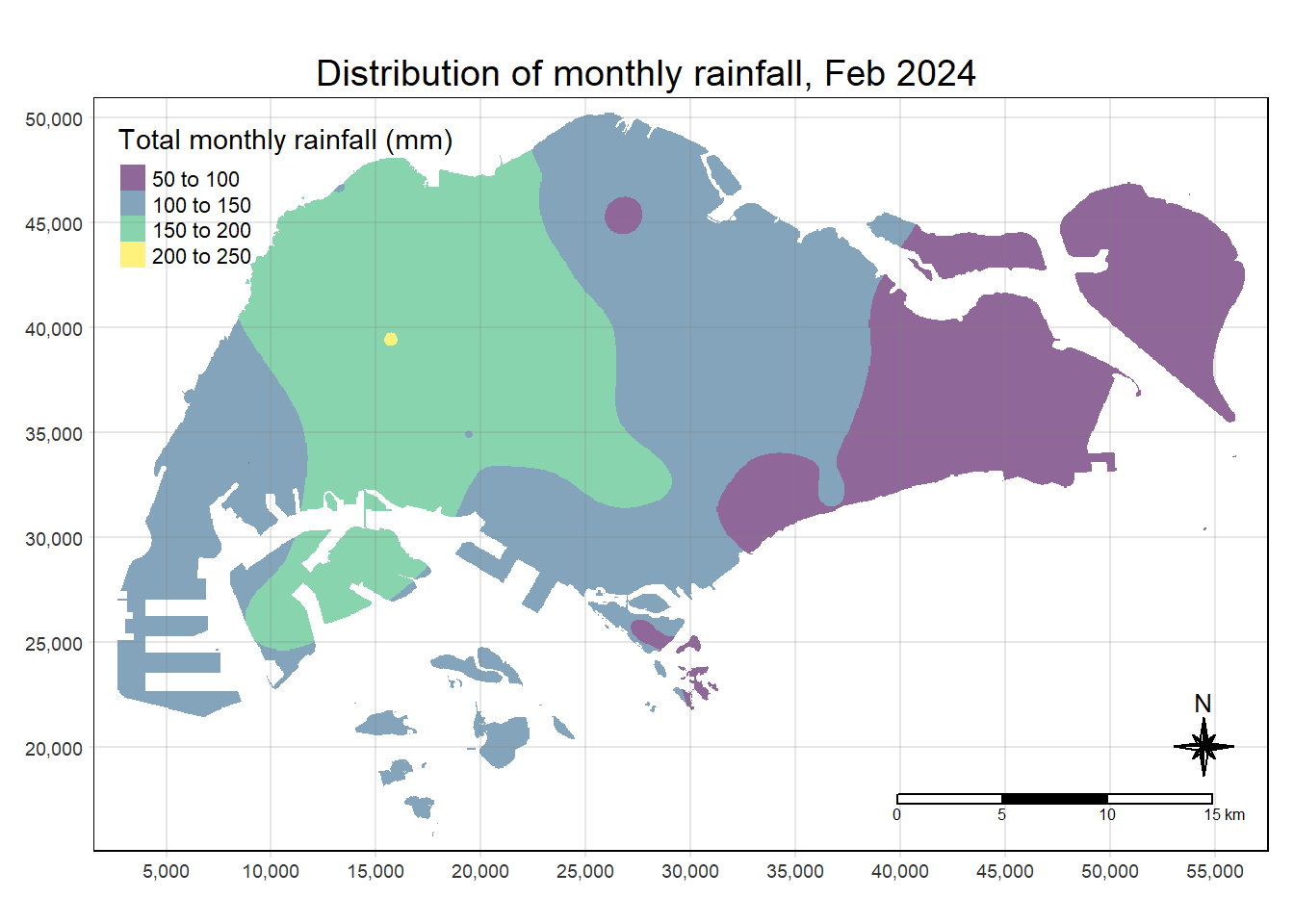
Reference
Olea, Ricardo A. (2006-07) “A six-step practical approach to semivariogram modeling”, Stochastic Environmental Research and Risk Assessment, 2006-07, Vol.20 (5), p.307-318. SMU e-journal.